Бывает так, что долго-долго собираюсь написать про какую-то тему и не нахожу на это время, а потом приходит человек и задает на эту тему вопрос (спасибо тебе, человек!), после которого находятся силы и время сделать разбор интересной темы.
Речь пойдет об организации памяти в JVM и таком явлении как String pool, а также почему нельзя так просто взять и удалить секретную информацию из памяти android приложения.
Внутри много картинок!

Очень поверхностный ликбез
Все строки в JVM являются неизменяемыми и создаются в области памяти, которая называется “куча” (heap). Внутри кучи есть еще одна область памяти, которая называется string pool. В эту область памяти, строки попадают автоматически, если создаются с помощью двойных кавычек. Строки могут быть также помещены в эту область памяти вручную при вызове метода intern(), а сам процесс помещения строк в пул называется интернированием.
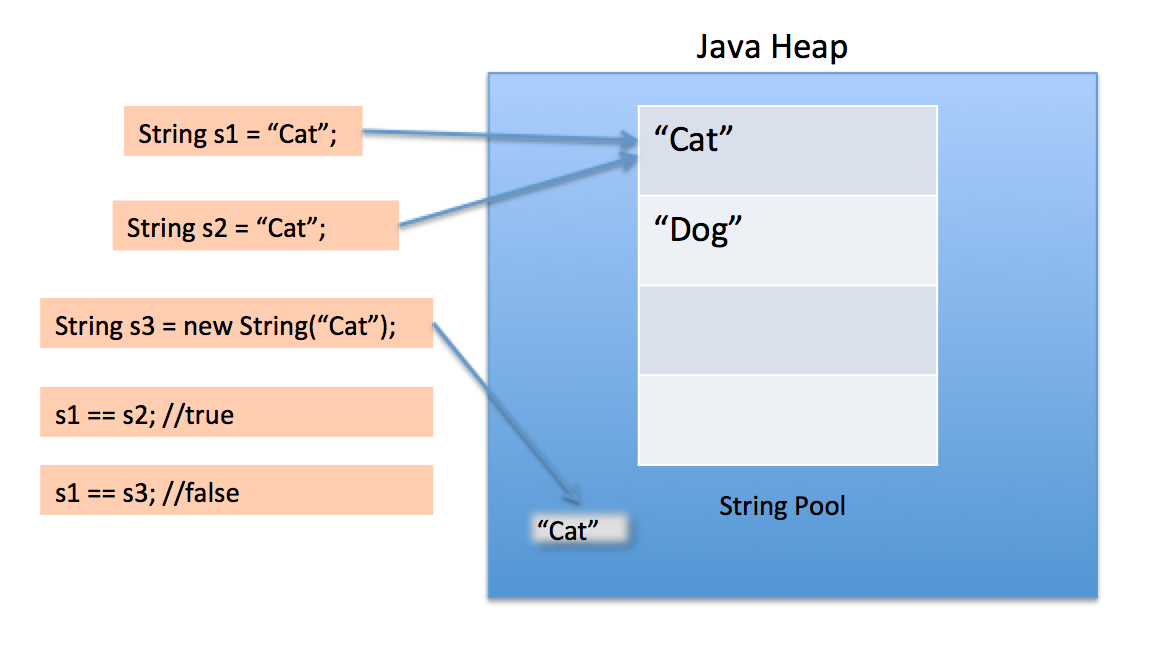
Зачем это нужно? Ради оптимизации! Вместо того чтобы создавать в куче много одинаковых строк, можно создать одну строку в пуле и далее ссылаться на нее. Это здорово экономит память.
Казалось бы, все хорошо, но есть пара нюансов, о которых следует помнить:
- Содержимое строк нельзя менять. При перезаписи строкового значения, будет создан новый объект, а старый ждет пока его соберет сборщик мусора.
- Сборщик мусора не собирает строки из пула
Эти оба два нюанса приводят к очень неприятным последствиям с точки зрения безопасности - невозможности гарантированно удалить строки из памяти приложения. А значит все токены, пароли и прочая конфиденциальная информация будет находиться в памяти приложения непредсказуемое количество времени. Почитать про пул строк более подробно можно по ссылке в конце статьи, а сейчас разберем на практических примерах как работает вся эта кухня и рассмотрим возможные решения этой проблемы.
Погружение в проблему

Чтобы наше путешествие в глубины JVM было удачным, нужно подготовить инструменты для создания дампов и последующего анализа памяти. Для создания дампов я использую самописный скрипт на bash:
|
|
А для разных этапов анализа нам понадобятся следующие инструменты:
- Утилита
stringsи ее ближайший другgrep - Android Studio Memory Profiler
- Парсер hprof файлов
Как это все будет задейстовано я покажу далее, а пока начнем с очень простого и надуманного примера.
Тому, кто захочет это повторить - придется делать очень много дампов. Более ленивых людей призываю просто наслаждаться происходящим ;)
Простой, надуманный пример
var token = "super_secret_token1337"
Log.d("Debug", token)
token = ""
System.gc()
Log.d("Debug", token)
Результат работы этого кода довольно предсказуем:

Был токен и не стало. Но, не все так однозначно. Давайте сделаем дамп памяти запущенного приложения и поищем в ней этот токен.
Строковый литерал предсказуемо оказался в пуле строк и даже принудительная сборка мусора не смогла его оттуда удалить. Используя знания полученные о том, что строки созданные с помощью конструктора в пул автоматически не попадают, попробуем сделать так чтобы наш секретный токен не оседал в памяти. Собирать строку будем через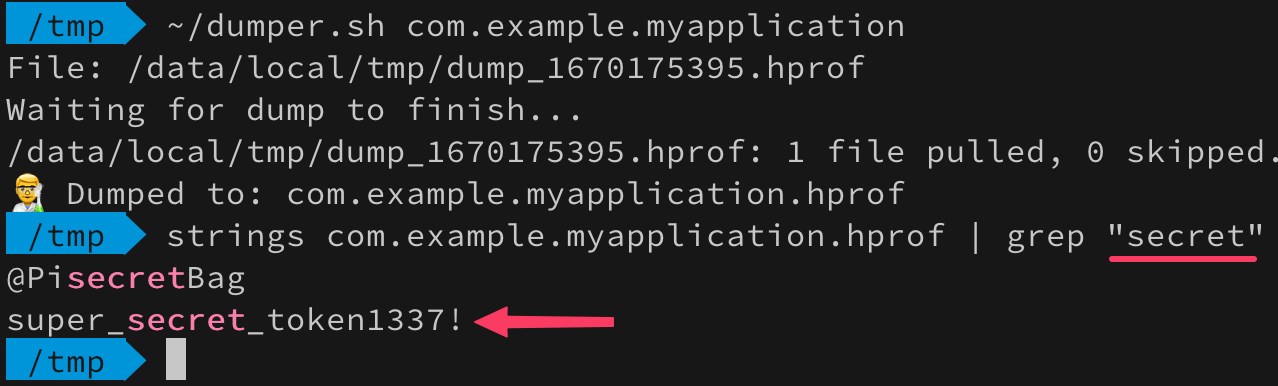
CharArray, чтобы вообще отказаться от строковых литералов.
var token = String(
charArrayOf(
's',
'u',
'p',
'e',
'r',
'_',
's',
'e',
'c',
'r',
'e',
't',
'_',
't',
'o',
'k',
'e',
'n',
'1',
'3',
'3',
'7'
)
)
Log.d("Debug", token)
token = ""
System.gc()
Log.d("Debug", token)
Гипотеза сработала!
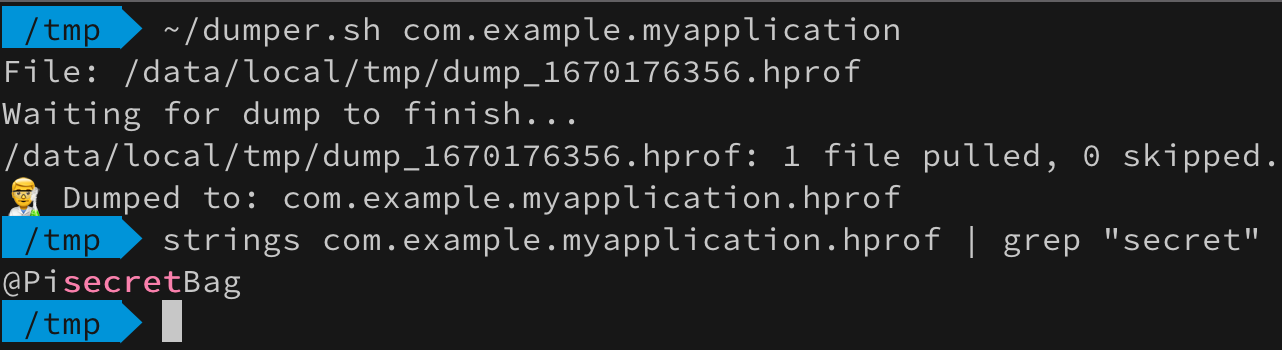
CharArray всех спас! На этом можно было бы закончить статью фразой “Используйте CharArray и да пребудет с вами безопасность”. Но давайте не будем торопиться с выводами. Немного модифицируем код и поменяем содержимое токена для наглядности:
|
|
Запускаем приложением, нажимаем на TextView и…
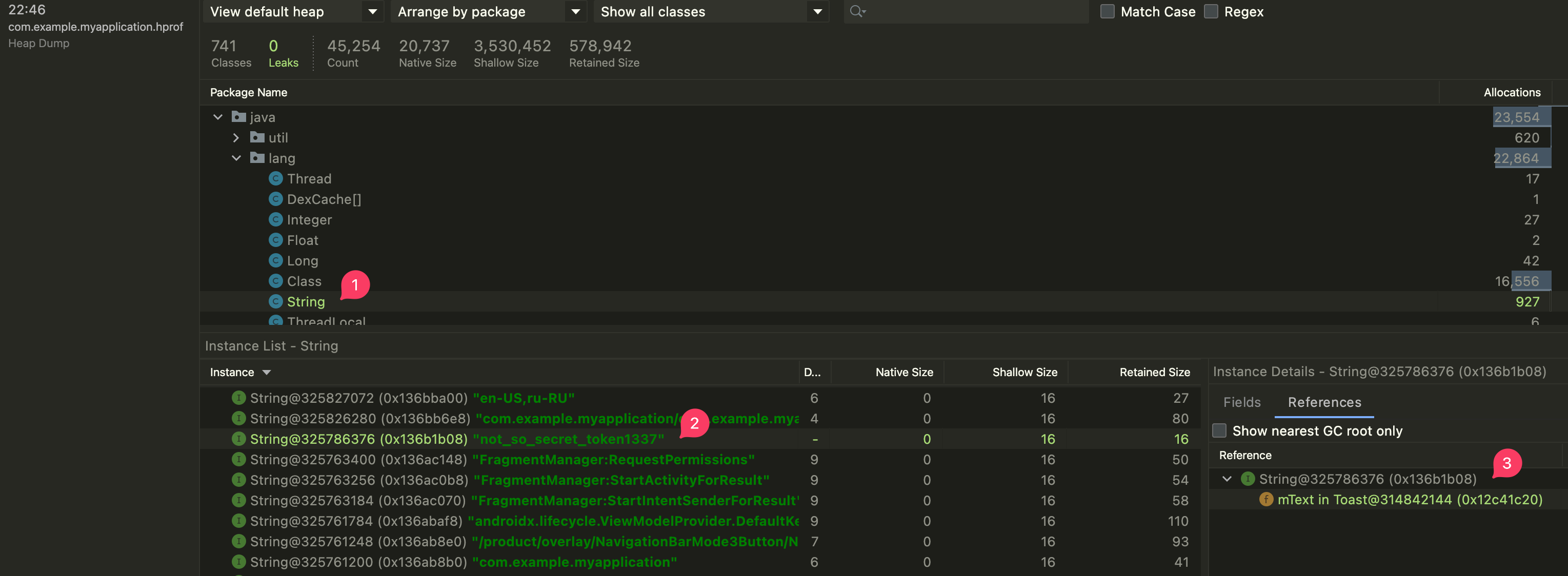
mText класса Toast. Но как так вышло?! Опытные android разработчики и прочие java-джедаи уже знают ответ. Для всех остальных, я открою страшный секрет: параметры в Java всегда передаются по значению. Другими словами - методы работают с копией данных, а не с оригиналом.
Более жизненный пример
До этого строки создавались “руками”, и у вас могли появиться сомнения в адекватности проводимых исследований. Все верно. Всегда нужно сомневаться в том, что читаешь в интернете! Поэтому все дальнейшие исследования будем проводить на классическом, клиент-серверном приложении, которое получает токены от сервера по https и сохраняет их в зашифрованном виде. Приложение забирайте тут.
Основной флоу работы приложения выглядит следующим образом:
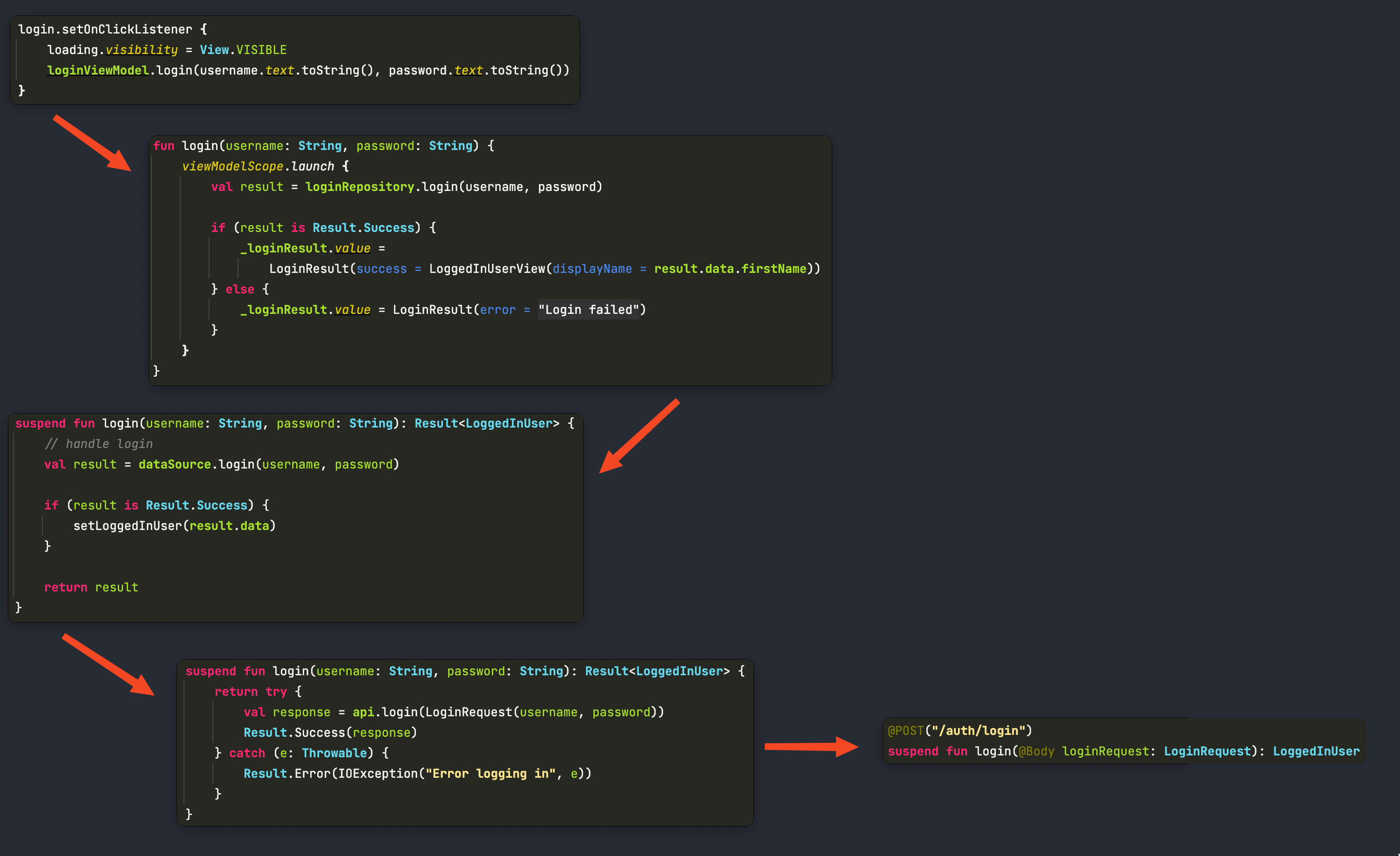
В ответ на запрос приходит модель описывающая залогиненного юзера и среди прочих данных возвращает токен для доступа к API:
|
|
Пройдем этот сценарий как есть, потом сделаем дамп и посмотрим где в памяти оседает токен.

Из скрина видно, что токен ссылается несколько объектов из показанной выше цепочки вызовов. Попробуем теперь “очистить память” после сохранения токена в защищенное хранилище и посмотреть, что в итоге попадет в дамп. Сначала нужно доработать метод setLoggedInUser() убрав из памяти ненужный токен:
private fun setLoggedInUser(loggedInUser: LoggedInUser) {
this.user = loggedInUser
preferences.edit {
putString("accessToken", user?.token)
}.also { // <- вся магия здесь
user?.token = ""
System.gc()
}
}
Запуск, дамп, и…
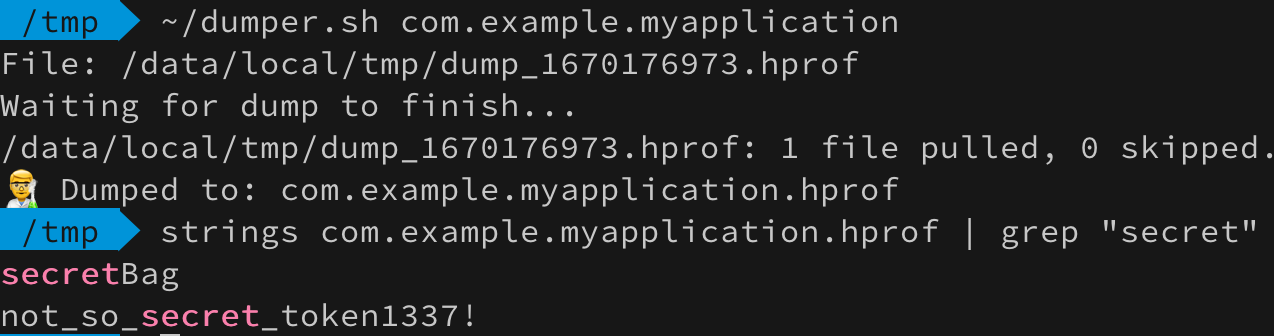
На привычном месте, среди длинных строк, токена больше нет. Только его зашифрованный вариант, который сохранился в преференсы. Неужели получилось? Спойлер: нет 🤪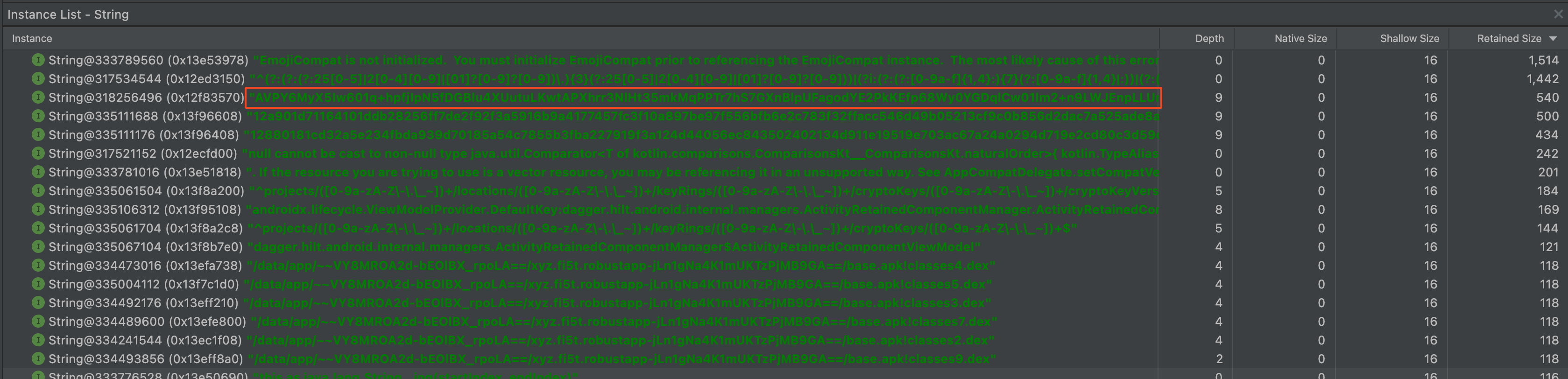
В профилировщике студии нет поиска по строкам (или я не нашел), поэтому пройдемся по дампу утилитой strings и погрепаем jwt токены:
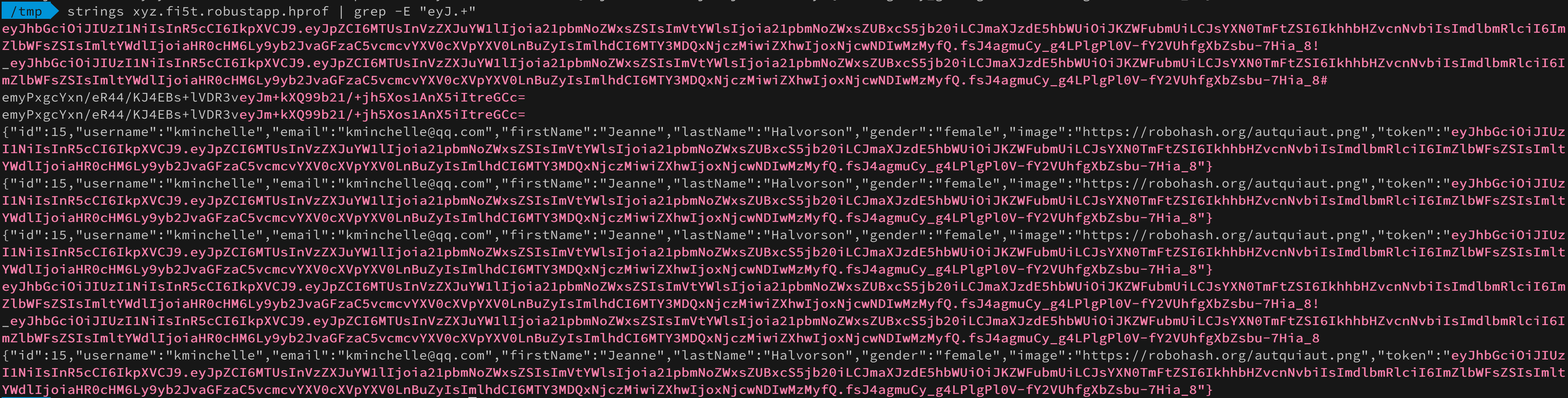
Покопаемся в куче
К дальнейшему анализу дампов, помимо уже имеющихся инструментов, подключим парсер формата hprof. Я взял готовую реализацию отсюда и немного допилил ее напильником чтобы она вообще работала, а не валилась с ошибкой. Доработанный вариант лежит здесь(ветка research) Стоит сказать, что до того, как найти эту реализацию я начал писать свою и концепт получился даже неплохим, но в итоге я решил не изобретать велосипед и взять что-то более-менее готовое. Если кому-то захочется написать такой парсер самостоятельно, то начать нужно отсюда.
Строки в JVM представляют из себя массив символов - char[] в кодировке UTF-16. А значит искать мы будем записи с типом HPROF_GC_PRIM_ARRAY_DUMP:
HPROF_GC_PRIM_ARRAY_DUMP dump of a primitive array
id array object ID
u4 stack trace serial number
u4 number of elements
u1 element type
4: boolean array
5: char array
6: float array
7: double array
8: byte array
9: short array
10: int array
11: long array
[u1]* elements
Записи (records) это элементы из которых состоит hprof файл. Они делятся на records и sub-records, и имеют разную структуру в зависимости от типа, который определяется тегом (первый байт записи).
Начнем с извлечения всех записей содержащих массивы символов:
|
|
Запуск парсера выдает интересные результаты. Совпадения нашлись, но их значительно меньше чем было при проходе утилитой strings. Всего два результата.

На этом месте нужно остановиться и немного подумать. Взглянув на возможные типы элементов, можно предположить, что строки также могут быть представлены как массивы байтов, а не символов. Модифицируем немного код парсера чтобы проверить эту гипотезу:
|
|
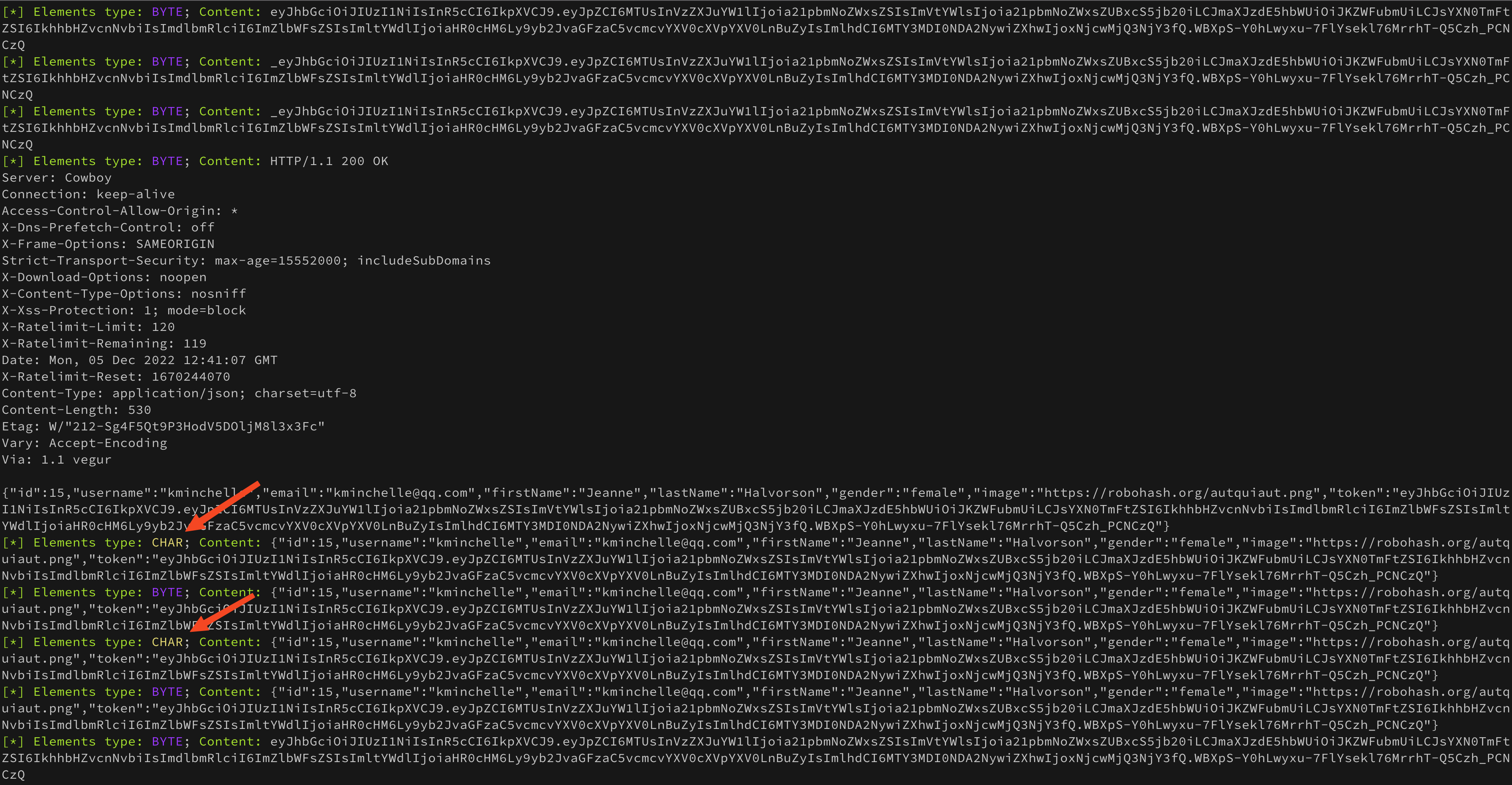
Отлично! Помимо уже имеющихся массивов символов появились байтовые массивы, которые содержат много интересных данных. Уже сейчас видно, что токен, несмотря на все наши усилия попал сразу в несколько кусков памяти, которые мы никак не контролируем.
И что теперь делать?
Порассуждаем. Токен, попал в несколько мест в куче в виде массивов двух типов, char[] и byte[], но это прозошло неявно, т.к. никаких массивов мы в коде не создавали. Что если попробовать получить больше контроля над этими всеми процессами и вместо строк начать использовать массивы байтов? А еще, байтовые массивы не являются иммутабельными и их можно затирать. Звучит как план!
На самом деле, можно пойти еще дальше и вместо байтового массива использовать байтовый буфер (ByteBuffer) с прямой аллокацией памяти.
A direct buffer refers to a buffer’s underlying data allocated on a memory area where OS functions can directly access it.
Начать использовать такой буфер нужно как можно раньше (ниже?) в архитектурном смысле. Самая первая точка, где мы получаем контроль над происходящим, находится в процедуре десериализации. Все, что происходит до этого является для нас черным ящиком. Поэтому начнем с написания адаптера, который будет сериализовать токен в ByteBuffer.
|
|
Даже на этом уровне нам уже приходится иметь дело со строками, но будем надеятся, что они там как-нибудь сами пропадут ;) Далее доработаем доменную модель пользователя:
|
|
Тут уже все хорошо, никаких строк не создается и мы практически в шаге от абсолютной безопасности! Осталось только очистить буфер после его сохранения в shared preferences.
|
|
Тут мы тоже без строк не обойдемся, к сожалению. SharedPreferences.Editor просто не умеет сохранять данные в виде массива байт. Но может нам повезет и это использование строк тоже никто не заметит? Тем более строка создается через конструктор, в пул строк попасть не должна, а значит мы все еще в безопасности!
Запускаем приложение, получаем токен с сервера, делаем дамп и смотрим на результат
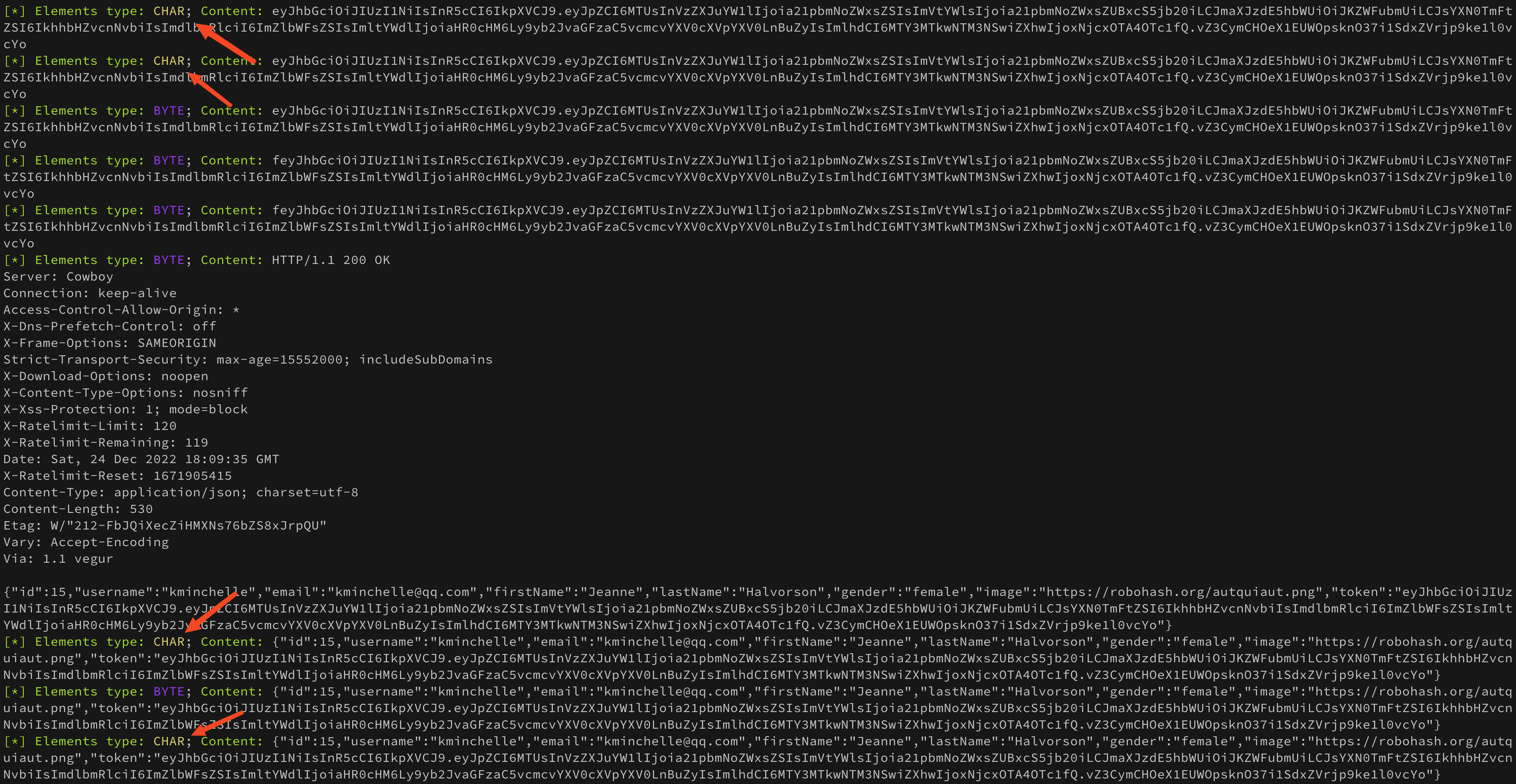
В голову сразу приходит вот эта картинка

Да, результат стал еще хуже чем был. И это еще не все данные, остальные не уместились на скриншоте. Что тут сказать… Не прокатило 🤪
Показанный выше способ с байтовыми буферами - вполне рабочий. Проблема не в нем. Она в том, что мы не контролируем большую часть того, что происходит с данными в приложении. Как с ними обращаются библиотеки, которые мы используем. Куда и как они их копируют и во что конвертируют. Чтобы избавиться от этой проблемы - нужно контролировать вообще все. В том числе сетевые библиотеки, сериализаторы, сохранять данные на диск в собственном формате. Все это должно быть самописным и не использовать JVM строки. Никто в здравом уме не будет этим заниматься.
Заключение
Стоило ли писать целую статью, если можно было в 3-5 предложений обрисовать ситуацию? Я считаю, что стоило. Хотябы для того чтобы прекратить поиск точки G возможностей затирать строки в памяти и сделать это осознанно. С доказательной базой, с инструментами для проверки гипотез и четким пониманием границ реализуемых механизмов. Я надеюсь, что прочитав ее вы узнали что-то новое и стали лучше понимать ту платформу с которой имеете дело в качестве разработчика или хакера.
Всех с наступающим Новым Годом! 🥳
Ссылки
- Руководство по String pool в Java
- Java is Pass by Value and Not Pass by Reference
- Guide to ByteBuffer